COME USARE I COMANDI DI VALIDAZIONE
Premessa
Per una trattazione dettagliata del problema della validazione si rimanda ai seguenti documenti in formato word nella cartella di installazione di Sargon:
•Criteri di validazione per Sargon
•Chi fa cosa
•Checksolvers
Inoltre, si rimanda alle seguenti sezioni del sito web di Castalia:
•Area Prodotti - Validazione (link)
•Area Servizi - Validazione (link)
e, soprattutto, al volume
La Validazione del Calcolo Strutturale, di Paolo Rugarli, EPC Libri, 2014, che costituisce la base di riferimento.
Sargon dispone di due utili strumenti: il priming e il menu di comandi dedicato alla validazione. Il priming serve ad aumentare il livello di attenzione dell'utente durante la creazione di un modello; il menu Validazione serve a confrontare in modo automatico due modelli indipendenti della stessa struttura, al fine di rilevare eventuali differenze, nonchè a ottenere ulteriori informazioni che possono essere controllate e verificate direttamente dall'utente stesso.
Da La Validazione del Calcolo Strutturale, Paolo Rugarli, EPC, 2014.
Il priming (pre-attivazione o sensibilizzazione) è un importante effetto osservato in una vasta pluralità di casi, che agisce sui processi di tipo 1, e quindi non consciamente. “Negli anni Ottanta gli psicologi scoprirono che essere esposti a una parola determina cambiamenti immediati e misurabili nella facilità con cui sono evocate molte parole correlate” ([64]).
Il priming è un meccanismo cognitivo generale e riguarda non solo le parole ma anche le esperienze complesse. Ad esempio è stato dimostrato che assentire con la testa (per motivi artificiosi indotti dagli sperimentatori) porta ad essere d’accordo e scuotere la testa in senso di diniego porta a dissentire, così come sorridere (stringendo una matita tra i denti) ad essere gai e far la faccia triste ad essere effettivamente tristi (nesso ideomotorio). Poiché tali esperimenti non sono contestabili, e hanno solide basi statistiche (dato che sono stati fatti su campioni significativi) si resta un po’ smarriti e l’idea che si aveva della singolarità della nostra specie, scema.
Ai fini della validazione, sentirsi sotto controllo può portare a prestazioni migliori di quelle ottenibili in un contesto libero e rilassato (la validazione è una attività stressante). A tale riguardo cito questo interessante esperimento fatto nella cucina di un ufficio di una università britannica, a Newcastle ( Bateson et al. [106], reperibile in rete), e descritto al grande pubblico da Kahneman nel suo best seller Pensieri Lenti e Veloci:
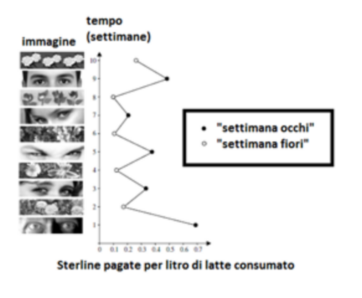
Figura 3.8. Tratto da [106]. Grafico coi gli incassi della “scatola dell’onestà” in funzione dell’effetto priming dato da immagini di fiori e di occhi.
Per molti anni i dipendenti di quell’ufficio avevano pagato il te o il caffè che prendevano durante il giorno mettendo soldi in una “scatola dell’onestà”. In ufficio era affisso l’elenco dei prezzi raccomandati. Un giorno, senza alcun preavviso o spiegazione, sopra quell’elenco fu attaccato un tabellone al quale venne affissa ogni settimana, per dieci settimane, un’immagine diversa. Nello specifico, vennero sostituite alternativamente rappresentazioni di fiori e immagini di occhi che parevano scrutare direttamente l’osservatore. Nessuno commentò il nuovo elemento d’arredo, ma i contributi alla scatola dell’onestà cambiarono significativamente. I poster e la somma che gli impiegati mettevano nella scatola dei soldi (relativamente alla quantità che consumavano) sono mostrati nella figura [3.6]. E meritano un’attenta analisi. La prima settimana dell’esperimento (come si vede alla base del diagramma), due occhi spalancati fissavano i bevitori di te o caffè, il cui contributo medio era di 70 pence per litro di latte. La seconda settimana, quando venne installato il poster dei fiori, i contributi medi scendevano a 15 pence. Il trend continuava. In media, gli utenti della cucina versarono nelle “settimane degli occhi” quasi il triplo dei soldi che diedero nelle “settimane dei fiori”. Sembrava che bastasse suggerire loro simbolicamente che erano osservati perché migliorassero il comportamento. Come si può immaginare, l’effetto si verificava senza che nessuno ne fosse consapevole. Ci credi, adesso, che anche tu rientreresti nello stesso modello di comportamento? [Kahneman, 64].
Questo esperimento è molto significativo anche per noi, tanto significativo che ho deciso di aggiungere ai miei programmi più importanti una opzione di “priming” che accluda gli occhi che scrutano (vari esemplari da alternarsi) come immagine da far apparire in posizioni strategiche sullo schermo o nei dialoghi, o in certi momenti di particolare importanza, come alla esecuzione di una selezione o della assegnazione di un carico. Ciò al fine di indurre nell’analista un effetto priming che lo porti ad essere più attento, con l’effetto finale che potrebbe essere simile a quello della figura 3.8.
Il priming è presente nella vista di Sargon e nei dialoghi che richiedono l'introduzione di dati fontamentali o comunque molto importanti. E' possibile attivare o disattivare il priming nella vista grafica attraverso il comando File-Impostazioni. L'immagine del priming nella vista cambia ogni giorno con ciclo di tre giorni.
Il priming nei dialoghi, invece, è fisso e non disattivabile. E' presente nei dialoghi in cui vanno definiti dati delicati, quali coordinate, lunghezze, azioni, vincoli, fattori di sicurezza, ecc.
Sargon dispone di un menu chiamato Validazione in cui sono presenti comandi che servono a creare informative e targhe dei modelli o di parti di essi. In entrambi i casi vengono create delle impronte, banali nel primo caso, non banali nel secondo.
Da La Validazione del Calcolo Strutturale, Paolo Rugarli, EPC, 2014.
Per impronta di un modello intendo in generale il valore assunto da una certa grandezza funzione dei dati di input o di output del modello, o meglio, usando la terminologia che ho appositamente introdotto nel precedente capitolo, funzione di una o più caratteristiche del modello.
Possiamo guardare al modello come a un’entità astratta che viene identificata mediante il controllo di una serie di dati ad essa propri, le impronte, le quali lo identificano univocamente. In analogia a quanto avviene con le persone umane, che sono identificate mediante le impronte digitali, o l’iride, o l’orecchio, un modello può essere probabilisticamente definito (e confrontato) mediante un certo numero di impronte, ovvero di dati numerici calcolabili a partire da esso.
Le impronte possono riferirsi a specifiche caratteristiche del modello di calcolo (ad esempio: i vincoli), e in tal caso sono dette impronte semplici o elementari. L’area logica alla quale si riferiscono le impronte è detta caratteristica o “parte del modello”. Dunque le impronte semplici si riferiscono a singole parti del modello. Ad esempio la quantità di luogo ideale (1D, 2D e 3D) di un modello è una impronta semplice della geometria dei suoi luoghi ideali.
Impronte che utilizzino informazioni di parti differenti di un modello sono dette impronte composte. Ad esempio il peso complessivo di un modello è una impronta composta della sua geometria e dei suoi materiali.
Elaborando le impronte semplici relative alle singole caratteristiche del modello, e quelle composte, sarà possibile pervenire alla definizione di una o più impronte complessive del modello, che identificano in senso probabilistico il modello allo studio. Le impronte complessive si possono anche indicare, per evitare confusione, come targhe del modello.
Un’ulteriore classificazione delle impronte le divide in impronte banali ed impronte non banali. Le prime sono calcolabili con relativo poco sforzo anche con mezzi di calcolo elementari, mentre le seconde richiedono mezzi di calcolo più elaborati e sono tipicamente destinate a essere calcolate mediante software specifici ed elaboratori di calcolo.
Nota che un’impronta non deve avere necessariamente un chiaro significato fisico, anzi, come vedremo, è possibile ideare impronte di un modello prive di significato fisico riconosciuto ma che però, per come sono costruite, hanno certe elevate capacità descrittive. Allora chiamo impronte fisiche impronte che abbiano un chiaro significato fisico alla luce della teoria, e impronte numeriche impronte che sono costruite con artifici numerici e che sono prive di un immediato significato fisico.
A differenza delle impronte digitali, che sono di per sé univoche (o meglio: hanno altissima probabilità di esserlo), le impronte semplici di un modello di per sé non lo sono. Ad esempio il peso teorico di un modello strutturale è una sua impronta fisica banale, ma non è univoca, perché due modelli differenti possono pesare allo stesso modo. Oppure, il numero delle combinazioni è un’altra impronta di un modello (numerica banale), ma è possibile che due insiemi di combinazioni siano differenti pur avendo lo stesso numero di combinazioni elementari. Dunque le singole impronte semplici prese non sono sufficienti a identificare un modello. Tuttavia, se viene controllato un numero sufficientemente alto di impronte, o se vengono utilizzate impronte complessive sufficientemente elaborate (funzioni di impronte elementari), diviene sempre meno probabile che il modello che ha le impronte controllate identiche a quelle di un altro modello, o ha le impronte controllate identiche alle impronte che dal modello che stiamo controllando ci aspettiamo, sia non conforme (ovvero sia un modello differente).
Proseguendo nella classificazione delle impronte distinguo tra impronte del modello ideale o impronte ideali, ed impronte del modello attuale, o impronte attuali. Ad esempio il peso di un modello è una impronta fisica ideale, mentre il volume medio di ciascun elemento finito è una impronta attuale (dipende dalla discretizzazione). Le impronte ideali non cambiano al variare del modello attuale, le impronte attuali sì. Due modelli attuali che abbiano impronte ideali identiche ma impronte attuali diverse sono due modelli attuali diversi del medesimo modello ideale. Come vedremo non ha senso cercare di verificare l’identità delle impronte attuali su modelli attuali differenti, mentre ha senso identificare per essi le impronte ideali.
Relativamente alla area del modello presa in considerazione distinguo ulteriormente tra impronte di input, se riferite al modello di ingresso, ed impronte di output, se riferite alla risposta strutturale di quel modello.
Infine, distinguo tra impronte estensive e impronte intensive, con l’ordinario significato della termodinamica: una impronta estensiva raddoppia se si considera un sistema ottenuto dalla riunione di due sistemi identici, mentre una impronta intensiva resta immutata. Ad esempio il volume è un’impronta estensiva, mentre la massima tensione di Von Mises è intensiva.
Passo ora ad esaminare le proprietà delle impronte. Le impronte sono valori numerici e possono o meno dipendere dal sistema di riferimento adottato per il modello e dalle unità di misura impiegate per descrivere le variabili di base (coordinate, forze, moduli di elasticità, eccetera).
Anziché mettere a punto dubbie e complicate metodologie atte a determinare un sistema di riferimento univoco per un modello di calcolo arrivato da chi sa dove (per esempio prendendo come assi globali gli assi baricentrici e principali dei volumi modellati), a me pare più sensato immaginare che i programmi vengano dotati di comandi utili a cambiare facilmente sistema di riferimento. Per cambiare sistema di riferimento gli assi devono roto traslare. Le operazioni da compiere sono abbastanza immediate e quindi non dovrebbe essere un problema che un tale comando (cambia sistema di riferimento al modello) diventi un comando standard.
Le impronte possono essere adimensionali, o, se dimensionali, devono espresse in un ben preciso sistema di unità di misura, che deve essere una specifica della impronta.
La introduzione delle impronte è stata fatta per uno scopo ben preciso, in vista di alcuni tipici problemi della validazione di modelli:
1.Dati due modelli attuali A e B dimostrare che A è identico a B.
2.Dato un modello attuale A ed un modello ideale I, dimostrare che il modello attuale A è coerente con il modello ideale I.
3.Dati due modelli attuali diversi A e B comprendere perché sono differenti.
Come si vedrà nel corso del lavoro, le attività 1,2 e 3 possono essere molto onerose per l’analista, e quindi in generale verrà del tutto spontaneo utilizzare mezzi di calcolo opportunamente allestiti al fine di automatizzare questo lavoro. Una parte di questo testo è infatti dedicata a descrivere procedure di controllo automatico che siano in grado di svolgere parte dei controlli. Naturalmente se e quando sarà possibile controllare un modello in modo semplice, ottenendo un certo grado di probabilità che i controlli siano sufficienti, non rinunceremo ad avvalerci di tale sistema, ma non pare neppure sensato rinunciare ad impiegare procedure automatiche che, se opportunamente progettate, possono rapidamente condurre o al medesimo risultato o, meglio ancora, ad un risultato più sicuro perché basato su probabilità di errore ancora minori. Comunque questa discussione sarà ripresa al cap. 10, dedicato agli esocontrolli. Dico sin da subito che i controlli di impronte automatici sono uno strumento nelle mani di una testa pensante ma non si possono in alcun modo sostituire ad essa.
Nella discussione che vede alcuni colleghi saldamente ancorati alle quattro operazioni ed altri tenacemente fautori delle procedure di calcolo più complesse, io penso che entrambi gli approcci siano meritevoli di attenzione, ma certo non è possibile sostenere che le quattro operazioni o l’intuito siano sempre sufficienti a controllare un modello in modo efficace.
Se è vero che l’attività di validazione è oggi in qualche misura un’arte, è anche vero che la disponibilità di procedure standardizzate ed automatizzate renderebbe un grande servizio senza nulla togliere alla possibilità di mantenere una quota parte del lavoro di validazione in un ambito più intuitivo. Dato che questo lavoro è un tentativo di inquadramento generale della materia, manterrò entrambi i punti di vista.
Le informative contengono dati e informazioni sul modello che l'utente può verificare di persona, mentre le targhe sono file "criptati" che contengono una descrizione completa e univoca del modello.Le targhe servono a confrontare in modo automatico modelli della stessa struttura realizzati separatamente e in modo indipendente, anche con programmi diversi. Di seguito sono ampiamente descritte le informative e le targhe.
Si tratta di impronte banali. Ovvero di grandezze numeriche che è facile tirare fuori con le 4 operazioni e che possono essere ottenute abbastanza facilmente con l'aiuto di una calcolatrice da tasca o di un foglio di lavoro.
Un'informativa è costituita dalle seguenti sezioni.
•Mesh info: informazioni sulla mesh.
•Ideal Loci without assigned properties (rounded sum): informazioni sui luoghi ideali degli elementi finiti.
•Constraints: informazioni sui vincoli.
•Material vector & assigns: informazioni sui materiali e sulla loro assegnazione agli elementi finiti.
•Cross section vector & assigns: informazioni sulle sezioni e sulla loro assegnazione agli elementi finiti.
•Cross section modifiers (beams and trusses): informazioni sui modificatori delle forme sezionali.
•Beam orientation: informazioni sull'orientazione degli elementi beam.
•Beam End releases: informazioni sugli svincoli delle travi.
•Semi rigid joints of beam elements: informazioni sui nodi semirigidi.
•Connection codes of beam elements: informazioni sui segni di connessione degli elementi beam.
•Masses: informazioni sulle masse.
•Load cases: informazioni sui casi di carico.
•Combinations (active set): informazioni sulle combinazioni dell'insieme (combiset) attivo.
•Actions assigned (overall sum of all load cases, here sum of rounded): informazioni sulle azioni applicate (somma di tutti i casi di carico).
•Action assigned: individual load cases (here sum of rounded): informazioni sulle azioni dei singoli casi di carico.
La targa è, metaforicamente, il DNA di un modello agli elementi finiti. Se si confrontanto targhe di modelli della stessa struttura realizzati in modo del tutto indipendente (da utenti diversi, eventualmente utilizzando programmi diversi), l'uguaglianza tra due targhe implica un'elevata probabilità di assenza di differenze tra i modelli confrontati. E' infatti poco probabile che due modelli creati indipendentemente possano avere targhe eguali essendo differenti.
Se il confronto automatico delle targhe evidenzia differenze significative tra i due modelli, ciò è indice del fatto che i due modelli sono differenti. Sarà quindi possibile andare a indagare in modo mirato per capire le cause delle differenze e individuare eventuali errori commessi in uno o nell'altro modello.
In termini pratici, una targa è un file alfanumerico in cui tutte le informazioni relative ai dati di un modello vengono opportunamente combinate e rielaborate per dare origine a pochi numeri significativi che Sargon può utilizzare per confrontare in modo automatico due modelli creati indipendentemente l'uno dall'altro.
Alcuni dati sono immediati, come ad esempio il numero totale dei nodi di un modello o il numero totale di elementi beam. Altri dati invece sono molto più complessi, come ad esempio quelli legati al luogo ideale di tutti gli elementi beam di un modello, dipendente dalla presenza di decine, centinaia o migliaia di elementi finiti, dalla loro posizione e orientazione nello spazio, dalle loro proprietà, ecc. Sargon traduce tutte queste informazioni in un unico dato "criptato", che un essere umano non è in grado di interpretare, perché privo di senso fisico, ma che il programma è in grado di confrontare con l'equivalente dato ottenuto su un altro modello. L'uguaglianza tra i due dati implica l'uguaglianza dei luoghi ideali degli elementi beam nei due modelli. Una differenza tra i due dati è sintomo di diversità tra i due modelli. Lo stesso viene fatto con gli altri tipi di elementi, ma anche con le proprietà sezionali e dei materiali, delle loro assegnazioni agli elementi, nonché con i vincoli e gli svincolo, con i casi di carico, le azioni, le combinazioni.
Poiché quando si crea un modello si introducono inevitabilmente delle approssimazioni nei dati (arrotondamenti, conversioni di unità di misura, ecc.), è importante stabilire quando due dati devono essere considerati uguali. Ad esempio, se la risultante delle azioni applicate in un caso di carico del modello A è pari a 1000kN, mentre per lo stesso caso di carico il modello B ha una risultante di 999.8kN, devo considerare tali valori come "uguali" oppure diversi?
Da un punto di vista ingegneristico, sappiamo che quella differenza potrebbe essere dovuta al fatto che in un modello le azioni sono state definite in Newton al millimetro quadrato, nell'altro invece in chilogrammi al metro quadrato. Nella conversione, si creano piccole differenze dovute agli arrotondamenti, ma presumibilmente non considereremo i due modelli diversi tra loro.
Lo stesso discorso può essere fatto per le coordinate dei nodi, per le dimensioni di una forma sezionale, ecc. Per stabilire se due dati siano da considerarsi uguali o diversi, l'utente stabilisce il numero di cifre significative da confrontare per le varie grandezze.
Per il numero di nodi, di elementi beam, di elementi piastra, ecc. il confronto è tra numeri interi che non vengono arrotondati: se un modello ha 1500 nodi e l'altro 1501, viene rilevata una differenza (e starà poi all'utente capirne la causa).
Nel caso dei luoghi ideali degli elementi della struttura, delle masse totali o delle risultanti delle azioni, il confronto è invece su grandezze influenzate dal numero di cifre significative chieste dall'utente. Tornando all'esempio precedente, se confrontiamo due modelli simili, in cui la risultante del primo caso di carico sia 1000kN per un modello e 999.8kN per l'altro, verrà rilevata una differenza solo se il numero di cifre significative utilizzato per le azioni nelle due targhe è maggiore di 3. Con tre cifre significative, infatti, entrambe le targhe riporteranno una risultante di 1000kN è ci sarà quindi uguaglianza. Sta all'utente stabilire il numero ottimale di cifre significative per ciascuna grandezza, in relazione al problema allo studio e al livello di tolleranza desiderato nel valutare l'uguaglianza di due modelli. Non è in ogni caso sensato confrontare due targhe che per una stessa grandezza utilizzino numeri di cifre significative diverse.
Lo stesso vale per i luoghi. Se ad esempio nei modelli si introducono dati leggermente diversi relativamente allo spessore di determinati elementi plate (differenze legate alla conversione, ecc.) la differenza verrà rilevata solo oltre un certo numero di cifre significative.
Analogamente, per il luogo ideale degli elementi truss, se le coordinate dei nodi sono leggermente diverse a causa di approssimazioni nella definizione dei dati, si dovranno ridurre opportunamente le cifre significative se si vuole che tali approssimazioni siano trascurate. Riducendo troppo il numero di cifre significative, il confronto non risulterà significativo.
I valori scritti in una targa sono riassumibili in:
•numero di oggetti di ciascuna tipologia (n° nodi, n° beam, n° truss, n° piastre, n° membrane, n° solidi, n° molle);
•numero di gradi di libertà del modello;
•impronte del luogo ideale dei vari elementi divisi per tipologia (beam, truss, membrane, ecc.);
•impronte dei vettori delle proprietà (materiali, sezioni, proprietà di piastre e membrane);
•impronte della assegnazione delle proprietà ai vari elementi;
•impronte della orientazione degli elementi beam;
•impronte della assegnazione di vincoli e svincoli;
•impronte del vettore dei casi di carico;
•impronte dei risultanti dei casi di carico (escluso il termico);
•impronte del vettore delle combinazioni;
•impronte delle masse nodali.
Una differenza in un dato non implica necessariamente che i modelli non siano confrontabili o che vi siano "errori". Prendiamo un esempio molto semplice: chiediamo a due utenti di modellare una piastra quadrata appoggiata su quattro lati, utilizzando elementi plate-shell a 4 nodi, possibilmente quadrati. Un utente potrà modellare la piastra con una discretizzazione di 50x50 elementi plate, l'altro utilizzerà 60x60 elementi plate. Il numero totale di elementi plate sarà inevitabilmente diverso ma, se i due non hanno commesso errori di definizione dei dati, i luoghi degli elementi plate saranno uguali. Poiché l'ordine di grandezza della discretizzazione è molto simile, potremo considerare simili i due modelli.
 e mesh 60x60 (a destra)")
Mesh di 50x50 elementi (a sinistra) e mesh 60x60 (a destra)
Se invece le due mesh fossero rispettivamente di 10x10 elementi e di 60x60elementi, pur essendoci uguaglianza tra i luoghi, sarebbe opportuno considerare diversi i due modelli, perché la risposta flessionale del modello con discretizzazione meno fitta, a causa del locking, sarebbe diversa da quella del modello con discretizzazione maggiore.
 e mesh 60x60 (a destra)")
Mesh di 10x10 elementi (a sinistra) e mesh 60x60 (a destra)
Naturalmente questo semplice esempio sarebbe verificabile anche senza l'ausilio di strumenti automatici, che invece diventano molto importanti in caso di modelli reali, anche molto complessi, in cui il confronto automatico può darci indicazioni generali sulla similitudine tra modelli e, in caso di differenze rilevate, permette di individuare l'area in cui tali differenze si manifestano (diversa orientazione degli elementi beam, differente risultante delle azioni di un caso di carico, assegnazione di svincoli errati o mancata assegnazione degli stessi, ecc.).
In casi reali, magari complessi, sarà difficile che confrontando due modelli indipendenti della stessa struttura ci sia un match completo di tutti i valori, anche qualora nessun modello sia affetto da differenze rilevanti. Come visto nell'esempio precedente, possono esserci differenze spiegabili e accettabili. L'uso degli strumenti automatici serve ad avere un'idea chiara delle similitudini e delle differenze, localizzando queste ultime per un approfondimento ulteriore.
Si ribadisce che il concetto di uguaglianza (o somiglianza) tra due modelli dipende dalla tolleranza desiderata, definita tramite il numero di cifre significative che devono essere confrontate per ciascuna grandezza.
Di seguito viene mostrato un esempio di targa. Il primo blocco mostra la struttura della targa; il secondo (compreso tra le stringhe _STRUCTFOOTPRINT ed _ENDSTRUCTFOOTPRINT) ha la stessa struttura, ed è riempito con i valori relativi al modello. La struttura non è fissa, ma dipende dal numero di casi di carico presenti. I dati sono espressi in formato esadecimale.
0 Number of significant digits used for signatures
1 IN0 IN1 IN2 IN3D
2 Ia0D1D Ia2D3D IaRIG Ia1DRig
3 Ia0Dxyz Ia1Dxyz Ia2Dxyz Ia3Dxyz
4 IMaterials IAssignDefMaterials IAssignRigMaterials ---
5 ICrossSections IAssignCrossSections IBeamOrientation ICrossSectionModifiers
6 IMThicknesses IPThicknesses IAssignMThicknesses IAssignPThicknesses
7 IaWinklerB IaWinklerP --- ---
8 -------- -------- IAssignSpringT IAssignSpringR
9 IaConstraints IaEndReleases IaSemirigid ---
10 ILoadCases ICombinations IaTotActions IaMasses
11 LoadCase 1 LoadCase 2 LoadCase 3 LoadCase 4
12 LoadCase 5 LoadCase 6 LoadCase 7 LoadCase 8
........................... up to MAX 120 load cases ........................
_STRUCTFOOTPRINT
0 00000004 00000004 00000004 00000004 00000004 00000004 00000004 00000000
1 000005E1 0000007E 00000330 00000DC4 00000000 00000000 00000000 00002106
2 69CA4AF5 F0657463 9E661180 9B184409 416A9148 F061ECC8 429EF026 F061ECC8
3 7EC112EE E412BA93 B86D5E68 E412B813 B86D5E68 E412B813 B86D5E68 E412B813
4 30E72AB0 00000000 EEA5115C FFFFFFFF EEA5115C FFFFFFFF 00000000 00000000
5 57F18A3C 01154697 E1B579A0 904AE04E C6382696 192ADCA3 EEA5115C FFFFFFFF
6 0012DB34 0012DB60 0012DB34 0012DB60 00000000 00000000 00000000 00000000
7 B86D5E68 E412B813 B86D5E68 E412B813 00000000 00000000 00000000 00000000
8 00000000 00000000 00000000 00000000 7BAB25BE E412BB45 7BAB25BE E412BB45
9 F78638FD E412BB1E 4DCF7642 38D7327F B86D5E68 E412B813 00000000 00000000
10 01B75755 00000000 000027FB 00000000 DF1BF37F 29CCF5A1 D199F6AD 3D982EC2
11 DF0F70F8 E42306AC 9DAED8E2 E41D164C C78B268D E41CDBE6 89A822CF E41D7CDC
12 E33D5772 40080AFF 00000000 00000000 00000000 00000000 00000000 00000000
_ENDSTRUCTFOOTPRINT
Quando vengono automaticamente confrontate due targhe, ciascun dato della targa del modello A viene confrontato con il corrispondente dato della targa del modello B. Se sono diversi, verrà segnalato un "mistmatch".
Targa modello A
...
12 E33D5772 4080AFF 00000000 00000000 00000000 00000000 00000000 00000000
...
Targa modello B
...
12 E33D5413 50151BDD 00000000 00000000 00000000 00000000 00000000 00000000
...
Se andiamo a vedere a cosa corrisponde il primo valore della riga 12, capiamo che c'è una differenza nel caso di carico 5. Il programma confronta in modo automatico tutti i dati, quindi stampa un riepilogo di tutte le corrispondenze (matches) e di tutte le differenze (different). Di seguito è riportato un esempio di file di confronto tra due modelli.
Number of spring: matches
Number of trusses: matches
Number of beams: matches
Number of membranes: matches
Number of plates: matches
Number of solid: matches
Number of degrees of freedom: matches
Ideal locus of translational spring: matches
Ideal locus of rotational spring: matches
Ideal locus of trusses: matches
!!! Ideal locus of Bernoulli beam: different
Ideal locus of Timoshenko beam: matches
Ideal locus of rigid trusses: matches
Ideal locus of rigid beams: matches
Ideal locus of trusses rigid-offsets: matches
Ideal locus of beams rigid-offsets: matches
Ideal loci of springs Ix (coords Y, Z): matches
!!! Ideal loci of springs Iy (coords X, Z): different
Ideal loci of springs Iz (coords X, Y): matches
!!! Ideal loci of springs Ixy (coords X, Y): different
Ideal loci of springs Iyz (coords Y, Z): matches
Ideal loci of springs Izx (coords Z, X): matches
Materials vector: matches
Material assignment of deformable elements: matches
Material assignment of rigid elements: matches
Cross-sections vector: matches
Cross section assignment: matches
!!! Beam orientation: different
Beam orientation: Ix (coords Y, Z): matches
Beam orientation: Iy (coords X, Z): matches
Beam orientation: Iz (coords X, Y): matches
!!! Beam orientation: Ixy (coords X, Y): different
!!! Beam orientation: Iyz (coords Y, Z): different
Beam orientation: Izx (coords Z, X): matches
Cross section modifiers: matches
Translational springs assignment: matches
Rotational springs assignment: matches
End releases assignment: matches
Semi rigid assignment: matches
!!! Constraints assignment: different
Ideal loci of point times constraint code: Ix (coords Y, Z): matches
!!! Ideal loci of point times constraint code: Iy (coords X, Z): different
Ideal loci of point times constraint code: Iz (coords X, Y): matches
Ideal loci of point times constraint code: Ixy (coords X, Y): matches
Ideal loci of point times constraint code: Iyz (coords Y, Z): matches
Ideal loci of point times constraint code: Izx (coords Z, X): matches
Load case vector: matches
!!! Overall actions (no thermal): different
Overall masses: matches
Combination vector light footprint: matches
Consideriamo, ad esempio, il confronto tra il numero di nodi del modello A e il numero di nodi del modello B; potremo avere una delle due condizioni seguenti:
Number of nodes: matches
oppure
!!! Number of nodes: different
Nel primo caso, il numero di nodi del modello A è uguale al numero di nodi del modello B; nel secondo caso è stata riscontrata una differenza.
La esatta descrizione del modo in cui la targa viene creata esula dagli scopi di questa guida. Approfondimenti significativi relativi alle impronte ed alle targhe sono disponibili nel volume La validazione del calcolo strutturale, di Paolo Rugarli, pubblicato da EPC nel 2014.